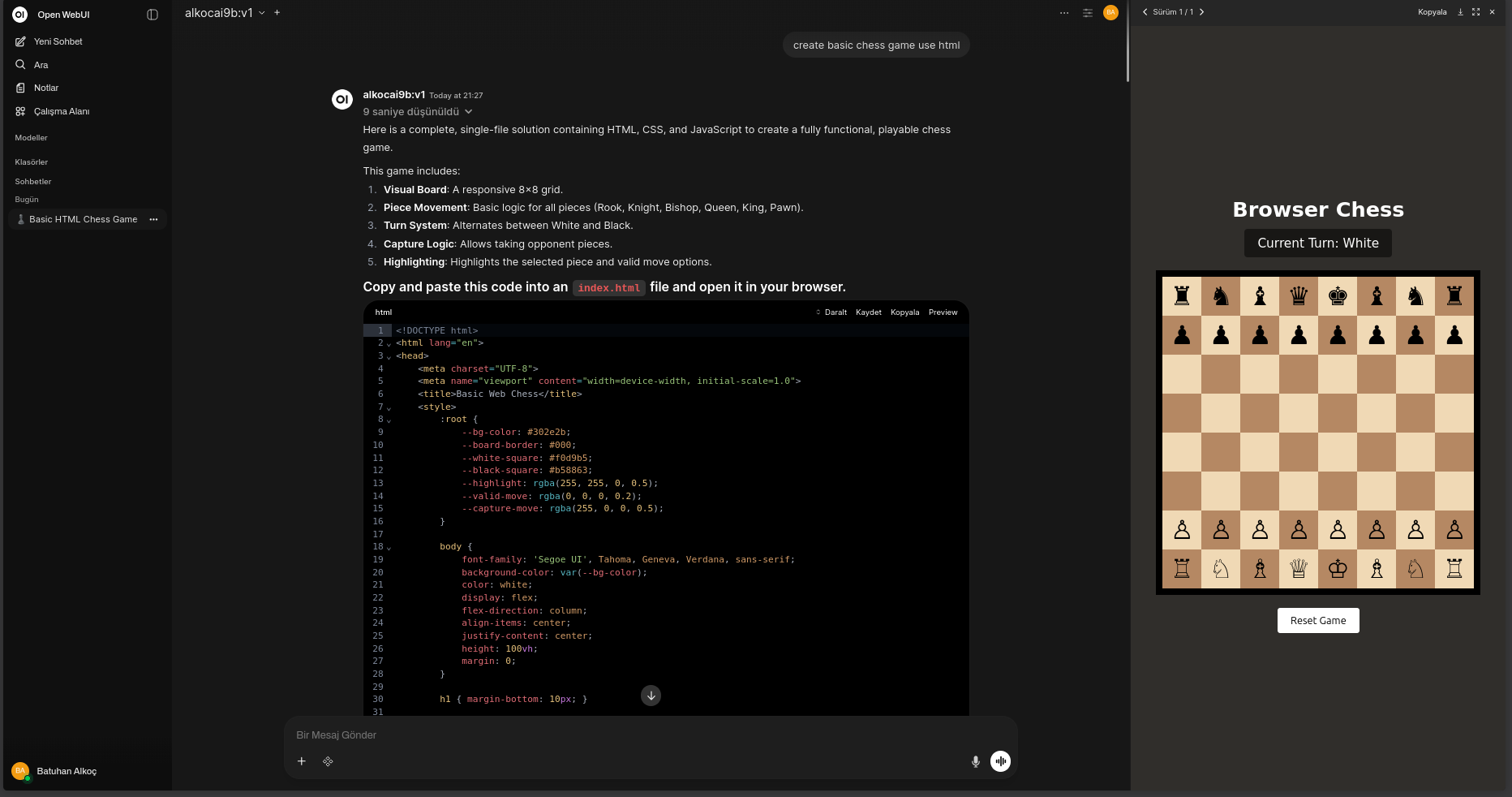
Bu rehber, tamamen gerçek deney ve hatalardan doğdu. Bir AI ile saatlerce uğraşarak öğrendiklerimizi sizinle paylaşıyoruz — teorik değil, elle tutulur.
İçindekiler
- Ollama Nedir?
- Kurulum
- HuggingFace'den Model İndirme
- Modelfile Oluşturma
- Model Boyutu ve Performans Karşılaştırması
- GPU Optimizasyonu
- Quantization Nedir?
- VS Code Entegrasyonu
- Cursor Entegrasyonu
- OpenWebUI Kurulumu
- Karşılaşılan Sorunlar ve Çözümler
1. Ollama Nedir?
Ollama, büyük dil modellerini (LLM) kendi bilgisayarında çalıştırmana olanak tanıyan açık kaynaklı bir araç. Bulut tabanlı AI servislerine (OpenAI, Anthropic vb.) alternatif olarak:
- Gizlilik: Veriler bilgisayarından çıkmıyor
- Maliyet: Aylık abonelik yok
- Offline: İnternet bağlantısı gerekmez
- Özelleştirme: Modeli istediğin gibi yapılandırabilirsin
2. Kurulum
Linux (Ubuntu/Debian)
curl -fsSL https://ollama.com/install.sh | sh
Servis olarak başlat:
systemctl enable ollama
systemctl start ollama
ollama --version
Dışarıdan erişim için (sunucu kurulumu):
# /etc/systemd/system/ollama.service.d/override.conf
[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434"
systemctl daemon-reload
systemctl restart ollama
Windows (WSL)
# PowerShell - WSL kur
wsl --install
# WSL Ubuntu'ya gir
wsl
# İçinde Ollama kur
curl -fsSL https://ollama.com/install.sh | sh
WSL'de Ollama'yı arka planda çalıştırmak için:
ollama serve &
Windows'ta native çalıştırmak istersen ollama.com'dan .exe indirebilirsin.
Doğrulama
# Model indir ve test et
ollama pull qwen3.5:0.8b
ollama run qwen3.5:0.8b "Merhaba, nasılsın?"
# Çalışan modelleri listele
ollama list
3. HuggingFace'den Model İndirme
Ollama'nın registry'sinde olmayan veya özel quantization istediğin modeller için HuggingFace'i kullanabilirsin.
huggingface-cli Kurulumu
pip install huggingface_hub
GGUF Formatında İndirme
# Qwen3.5 9B Q4_K_M örneği
huggingface-cli download unsloth/Qwen3.5-9B-GGUF \
--include "Qwen3.5-9B-Q4_K_M.gguf" \
--local-dir ~/ollama/
# Qwen3.5 0.8B Q8 örneği
huggingface-cli download unsloth/Qwen3.5-0.8B-GGUF \
--include "*Q8*" \
--local-dir ~/ollama/
curl ile İndirme (alternatif)
# HuggingFace direct download
curl -L "https://huggingface.co/unsloth/Qwen3.5-9B-GGUF/resolve/main/Qwen3.5-9B-Q4_K_M.gguf" \
-o ~/ollama/Qwen3.5-9B-Q4_K_M.gguf
Öneri: Unsloth tarafından quantize edilmiş modeller kaliteli ve yaygın olarak test edilmiş. Başlangıç için onları tercih et.
4. Modelfile Oluşturma
Modelfile, modelin nasıl davranacağını tanımlayan yapılandırma dosyası. Registry'den indirilen modeller için genellikle gerekli değil ama GGUF dosyasından model oluşturuyorsan şart.
Temel Yapı
# Model kaynağı (registry veya local GGUF)
FROM /home/user/ollama/Qwen3.5-9B-Q4_K_M.gguf
# Qwen3.5 için gerekli renderer ve parser
RENDERER qwen3.5
PARSER qwen3.5
# Performans parametreleri
PARAMETER num_gpu 999 # Tüm layer'ları GPU'ya at
PARAMETER num_ctx 16384 # Context penceresi (token)
PARAMETER num_thread 12 # CPU thread sayısı (GPU yoksa)
# Yanıt kalitesi parametreleri
PARAMETER temperature 0.7 # Yaratıcılık (0=deterministik, 1=yaratıcı)
PARAMETER top_p 0.9
PARAMETER top_k 20
PARAMETER repeat_penalty 1.1
PARAMETER repeat_last_n 64
# Chat formatı (Qwen modelleri için)
TEMPLATE """{{- if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}
{{- range .Messages }}
{{- if eq .Role "user" }}<|im_start|>user
{{ .Content }}<|im_end|>
<|im_start|>assistant
{{ else if eq .Role "assistant" }}{{ .Content }}<|im_end|>
{{ end }}
{{- end }}"""
# Sistem promptu
SYSTEM "You are a helpful assistant. Reply in the same language the user writes in."
Model Oluşturma ve Güncelleme
# Oluştur
ollama create benim-modelim:v1 -f ./Modelfile
# Güncelle (önce sil, sonra yeniden oluştur)
ollama rm benim-modelim:v1
ollama create benim-modelim:v1 -f ./Modelfile
# Kontrol et
ollama show benim-modelim:v1 --verbose
Nothink Modu (Hızlı Yanıt)
Qwen3.5 varsayılan olarak düşünme (thinking) modu içeriyor. Kod asistanı gibi hızlı yanıt gerektiren kullanım senaryolarında bunu kapatabilirsin:
# Template içinde her user mesajına /no_think ekle
TEMPLATE """...
{{ .Content }} /no_think<|im_end|>
..."""
5. Model Boyutu ve Performans Karşılaştırması
Testler RTX 3060/3070 (8GB VRAM) ve i5-12400F (12 core) üzerinde yapılmıştır.
Token/s Karşılaştırması
| Model | Quantization | Boyut | VRAM | Token/s | Kalite |
|---|---|---|---|---|---|
| Qwen3.5 0.8B | Q8 | ~800MB | CPU | 7.75 | ⭐⭐ |
| Qwen3.5 0.8B | Q8 | ~800MB | GPU | ~150+ | ⭐⭐ |
| Qwen3.5 4B | Q8 | ~4.5GB | GPU | 92.61 | ⭐⭐⭐ |
| Qwen3.5 9B | Q4_K_M | 5.63GB | GPU | 57.25 | ⭐⭐⭐⭐ |
| Qwen3.5 9B | Q5_K_M | 6.52GB | GPU | ~50 | ⭐⭐⭐⭐ |
| Qwen3.5 27B | Q1 | ~6.8GB | Hybrid | ~15 | ⭐⭐⭐ |
8GB VRAM İçin Öneriler
✓ En İyi Seçim: 9B Q4_K_M (57 tok/s, iyi kalite, 7.1GB)
✓ Alternatif: 4B Q8 (92 tok/s, hızlı, 6.8GB)
✓ Hız Öncelikliyse: 4B Q4 (100+ tok/s, orta kalite)
✗ Kaçın: 27B Q1 (hybrid mod, yavaş, düşük kalite)
Donanıma Göre Model Seçimi
| VRAM | Öneri |
|---|---|
| 4GB | 7B Q2, 4B Q4 |
| 8GB | 9B Q4_K_M, 4B Q8 |
| 12GB | 14B Q4, 9B Q8 |
| 16GB | 14B Q8, 27B Q4 |
| 24GB | 32B Q4, 27B Q8 |
6. GPU Optimizasyonu
Neden GPU Önemli?
CPU vs GPU temel farkı paralel işlem kapasitesi:
CPU: 12 çekirdek → 12 paralel işlem
GPU: 4096 çekirdek → 4096 paralel işlem
LLM'ler matris çarpımı yapıyor — GPU bu iş için optimize edilmiş. Sonuç:
Aynı model, CPU: 7-15 tok/s
Aynı model, GPU: 50-100 tok/s (5-10x hızlı)
Hybrid Mod (Kısmi GPU)
Model VRAM'e tam sığmadığında Ollama, bazı layer'ları GPU'ya bazılarını CPU'ya yükler. Bu durumda CPU darboğaz oluşturur:
Layer 1-25 → GPU (hızlı)
Layer 26-40 → CPU (yavaş)
────────────────────────
Sonuç: Tüm hız CPU'nun hızına iner
GPU Kullanımını Zorlama
PARAMETER num_gpu 999 # Tüm layer'ları GPU'ya at
Eğer VRAM yetersizse hata alırsın — bu durumda context'i düşür:
PARAMETER num_gpu 999
PARAMETER num_ctx 8192 # 16384 yerine
VRAM Kullanımını İzleme
# Anlık VRAM durumu
nvidia-smi
# Canlı izleme
nvidia-smi dmon -s u
# btop ile izleme (GPU satırına bak)
btop
7. Quantization Nedir?
Quantization, model ağırlıklarını sıkıştırma işlemi. Her sayıyı daha az bit ile ifade ederek model boyutunu küçültürsün:
float32 → 32 bit (tam hassasiyet, dev boyut)
float16 → 16 bit
Q8_0 → 8 bit
Q4_K_M → 4 bit
Q2_K → 2 bit (çok bozuk)
Kalite ve Boyut Dengesi (9B model)
| Format | Boyut | Kalite |
|---|---|---|
| float32 | 36GB | %100 |
| float16 | 18GB | %99 |
| Q8_0 | 9.5GB | %97 |
| Q5_K_M | 6.5GB | %93 |
| Q4_K_M | 5.6GB | %90 |
| Q2_K | 3GB | %70 |
K_M ve K_S Farkı
- K_M (Medium): Daha iyi kalite, biraz daha büyük — genellikle önerilen
- K_S (Small): Biraz daha küçük, hafif kalite kaybı
4B Q8 mi, 9B Q4 mü?
Sık sorulan soru. Kısa cevap: 9B Q4 genellikle kazanır.
4B Q8: 4 milyar × yüksek hassasiyet = az bilgi, net ifade
9B Q4: 9 milyar × düşük hassasiyet = çok bilgi, hafif gürültü
Daha fazla parametre = daha fazla bilgi kapasitesi. Q4'ün getirdiği kayıp, 2x daha fazla parametrenin kazancını geçemiyor.
8. VS Code Entegrasyonu
Ollama for VS Code
Extension'ı yükle: VS Code Marketplace'den "Ollama" ara.
Kurulum sonrası:
Ctrl+Shift+P→ "Ollama: Select Model"- Modelini seç
Ctrl+Shift+P→ "Ollama: Chat"
Tools Capability Görünmüyor?
En yaygın sorun: model listede var ama "Tools" etiketi yok.
Çözüm 1 — Cache temizle:
Ctrl+Shift+P → Developer: Reload Window
Çözüm 2 — API'yi kontrol et:
curl -s http://localhost:11434/api/show \
-d '{"name":"model-adi"}' | python3 -m json.tool | grep -A5 "capabilit"
Eğer API tools döndürüyorsa sorun extension cache'inde, Reload Window çözüyor.
Çözüm 3 — Manifest sorunu:
GGUF'tan import edilen modeller bazen manifest oluşturmuyor. Registry'deki modeli base alıp GGUF'unu override et:
FROM qwen3.5:0.8b
# kendi parametrelerin...
Continue.dev (Önerilen)
VS Code'da daha güçlü entegrasyon için Continue.dev:
- Codebase indexing
- Otomatik context
- Tab autocomplete
- Ollama native destek
9. Cursor Entegrasyonu
Cursor doğrudan localhost'a bağlanamıyor — SSRF koruması var. Çözüm: Cloudflare Tunnel ile public URL.
Cloudflare Tunnel Kurulumu
# cloudflared kur
curl -L https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64 \
-o /usr/local/bin/cloudflared
chmod +x /usr/local/bin/cloudflared
# Tunnel başlat (hesap gerekmez)
cloudflared tunnel --url http://localhost:11434
Çıkan https://xxxx.trycloudflare.com URL'sini Cursor'a ekle:
Cursor Settings → Models → Add Model
Base URL: https://xxxx.trycloudflare.com/v1
API Key: ollama
Model Name: benim-modelim:v1
Güvenlik Notu: Public URL oluşturursan Cloudflare Access ile koru, yoksa herkes modelini kullanabilir.
Kendi Domainine Yönlendirme
Cloudflare hesabın varsa kalıcı domain yönlendirebilirsin:
# Hesap gerekli, kalıcı subdomain
cloudflared tunnel create ollama-tunnel
cloudflared tunnel route dns ollama-tunnel api.senindomain.com
10. OpenWebUI Kurulumu
ChatGPT benzeri arayüz için OpenWebUI, Ollama ile mükemmel çalışıyor.
Docker ile Kurulum
docker run -d \
--network=host \
-v open-webui:/app/backend/data \
-e OLLAMA_BASE_URL=http://localhost:11434 \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main
Tarayıcıdan http://localhost:3000 aç.
Docker Compose
version: '3'
services:
open-webui:
image: ghcr.io/open-webui/open-webui:main
network_mode: host
volumes:
- open-webui:/app/backend/data
environment:
- OLLAMA_BASE_URL=http://localhost:11434
restart: always
volumes:
open-webui:
docker compose up -d
11. Karşılaşılan Sorunlar ve Çözümler
❌ Model CPU'da Çalışıyor
Kontrol:
nvidia-smi # GPU kullanımına bak
Çözüm: Modelfile'a ekle:
PARAMETER num_gpu 999
❌ 500: memory layout cannot be allocated
Sorun: VRAM yetersiz.
Çözüm: Context'i düşür:
PARAMETER num_ctx 8192 # veya 4096
❌ CUDA error: out of memory
Sorun: Önceki model hâlâ VRAM'de.
Çözüm:
pkill -f "ollama runner"
sleep 3
nvidia-smi # VRAM boşaldı mı kontrol et
❌ VS Code'da Tools Görünmüyor
Çözüm:
Ctrl+Shift+P → Developer: Reload Window
❌ Manifest Dosyası Bulunamıyor
GGUF'tan import edilen modeller /root/.ollama/ yerine /usr/share/ollama/.ollama/ altında olabilir:
find / -path "*/ollama/models/blobs*" -type f 2>/dev/null | head -5
❌ Cursor'da SSRF Hatası
connection to private IP is blocked
Çözüm: Cloudflare Tunnel veya ngrok ile public URL oluştur (bkz. Cursor Entegrasyonu).
Özet
Yerel LLM kurulumu ilk bakışta karmaşık görünüyor ama birkaç temel prensibi anladıktan sonra oldukça yönetilebilir:
- Model seçimi: 8GB VRAM için 9B Q4_K_M altın standart
- GPU optimizasyonu:
num_gpu 999+ context dengesi kritik - Quantization: Daha fazla parametre > daha yüksek hassasiyet (genellikle)
- Entegrasyon sorunları: Çoğunlukla cache veya manifest sorunu, Reload Window ile çözülüyor
- Cursor/remote erişim: Cloudflare Tunnel şart
Running Your Own Local AI: A Complete Ollama Setup Guide
This guide was born from real experimentation and real mistakes. Everything here was learned hands-on — not from documentation, but from things breaking and getting fixed.
Table of Contents
- What is Ollama?
- Installation
- Downloading Models from HuggingFace
- Creating a Modelfile
- Model Size & Performance Benchmarks
- GPU Optimization
- What is Quantization?
- VS Code Integration
- Cursor Integration
- OpenWebUI Setup
- Common Errors and Fixes
1. What is Ollama? {#what-is-ollama}
Ollama lets you run large language models locally on your own machine. Instead of relying on cloud-based AI services like OpenAI or Anthropic, you get:
- Privacy: Your data never leaves your machine
- Cost: No monthly subscription
- Offline access: No internet connection required
- Customization: Full control over model behavior
2. Installation {#installation}
Linux (Ubuntu/Debian)
curl -fsSL https://ollama.com/install.sh | sh
Start as a system service:
systemctl enable ollama
systemctl start ollama
ollama --version
To allow external access (server setup):
# /etc/systemd/system/ollama.service.d/override.conf
[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434"
systemctl daemon-reload
systemctl restart ollama
Windows (WSL)
# Install WSL
wsl --install
# Enter Ubuntu
wsl
# Install Ollama inside WSL
curl -fsSL https://ollama.com/install.sh | sh
To run Ollama in the background under WSL:
ollama serve &
For native Windows installation, download the .exe from ollama.com.
Verify Installation
ollama pull qwen3.5:0.8b
ollama run qwen3.5:0.8b "Hello, how are you?"
ollama list
3. Downloading Models from HuggingFace {#downloading-models}
For models not available in Ollama's registry, or when you need a specific quantization, use HuggingFace directly.
Install huggingface-cli
pip install huggingface_hub
Download GGUF Models
# Qwen3.5 9B Q4_K_M
huggingface-cli download unsloth/Qwen3.5-9B-GGUF \
--include "Qwen3.5-9B-Q4_K_M.gguf" \
--local-dir ~/ollama/
# Qwen3.5 0.8B Q8
huggingface-cli download unsloth/Qwen3.5-0.8B-GGUF \
--include "*Q8*" \
--local-dir ~/ollama/
Download with curl
curl -L "https://huggingface.co/unsloth/Qwen3.5-9B-GGUF/resolve/main/Qwen3.5-9B-Q4_K_M.gguf" \
-o ~/ollama/Qwen3.5-9B-Q4_K_M.gguf
Tip: Models quantized by Unsloth are high quality and widely tested. Start with those.
4. Creating a Modelfile {#modelfile}
A Modelfile defines how your model behaves. If you're pulling from the registry, you usually don't need one — but if you're importing a local GGUF file, it's required.
Basic Structure
# Model source (registry or local GGUF path)
FROM /home/user/ollama/Qwen3.5-9B-Q4_K_M.gguf
# Required for Qwen3.5 models
RENDERER qwen3.5
PARSER qwen3.5
# Performance
PARAMETER num_gpu 999 # Push all layers to GPU
PARAMETER num_ctx 16384 # Context window size (tokens)
PARAMETER num_thread 12 # CPU threads (relevant if no GPU)
# Output quality
PARAMETER temperature 0.7
PARAMETER top_p 0.9
PARAMETER top_k 20
PARAMETER repeat_penalty 1.1
PARAMETER repeat_last_n 64
# Chat template (required for Qwen models)
TEMPLATE """{{- if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}
{{- range .Messages }}
{{- if eq .Role "user" }}<|im_start|>user
{{ .Content }}<|im_end|>
<|im_start|>assistant
{{ else if eq .Role "assistant" }}{{ .Content }}<|im_end|>
{{ end }}
{{- end }}"""
SYSTEM "You are a helpful assistant. Reply in the same language the user writes in."
Build and Rebuild
# Create
ollama create my-model:v1 -f ./Modelfile
# Update (delete first, then recreate)
ollama rm my-model:v1
ollama create my-model:v1 -f ./Modelfile
# Verify
ollama show my-model:v1 --verbose
Disabling Thinking Mode
Qwen3.5 has a built-in thinking (reasoning) mode. For use cases like coding assistants where you want fast, direct responses, you can disable it:
TEMPLATE """...
{{ .Content }} /no_think<|im_end|>
..."""
5. Model Size & Performance Benchmarks {#benchmarks}
Tested on RTX 3060/3070 (8GB VRAM) with an i5-12400F (12 cores).
Tokens per Second
| Model | Quantization | Size | VRAM | Tok/s | Quality |
|---|---|---|---|---|---|
| Qwen3.5 0.8B | Q8 | ~800MB | CPU | 7.75 | ⭐⭐ |
| Qwen3.5 0.8B | Q8 | ~800MB | GPU | ~150+ | ⭐⭐ |
| Qwen3.5 4B | Q8 | ~4.5GB | GPU | 92.61 | ⭐⭐⭐ |
| Qwen3.5 9B | Q4_K_M | 5.63GB | GPU | 57.25 | ⭐⭐⭐⭐ |
| Qwen3.5 9B | Q5_K_M | 6.52GB | GPU | ~50 | ⭐⭐⭐⭐ |
| Qwen3.5 27B | Q1 | ~6.8GB | Hybrid | ~15 | ⭐⭐⭐ |
Recommendations for 8GB VRAM
✓ Best choice: 9B Q4_K_M (57 tok/s, good quality, 7.1GB)
✓ Speed priority: 4B Q8 (92 tok/s, fast, 6.8GB)
✓ Quality bump: 4B Q4 (100+ tok/s, medium quality)
✗ Avoid: 27B Q1 (hybrid mode, slow, low quality)
Model Selection by VRAM
| VRAM | Recommendation |
|---|---|
| 4GB | 7B Q2, 4B Q4 |
| 8GB | 9B Q4_K_M, 4B Q8 |
| 12GB | 14B Q4, 9B Q8 |
| 16GB | 14B Q8, 27B Q4 |
| 24GB | 32B Q4, 27B Q8 |
6. GPU Optimization {#gpu-optimization}
Why GPU Matters
The core difference between CPU and GPU comes down to parallel processing:
CPU: 12 cores → 12 operations in parallel
GPU: 4096 cores → 4096 operations in parallel
LLMs are essentially massive matrix multiplications — exactly what GPUs are built for. The result:
Same model, CPU: 7–15 tok/s
Same model, GPU: 50–100 tok/s (5–10x faster)
Hybrid Mode
When a model doesn't fully fit in VRAM, Ollama splits it — some layers on GPU, some on CPU. The CPU becomes the bottleneck:
Layers 1–25 → GPU (fast)
Layers 26–40 → CPU (slow)
─────────────────────────
Result: overall speed drops to CPU speed
Force GPU Usage
PARAMETER num_gpu 999
If you get a VRAM error, reduce context first:
PARAMETER num_gpu 999
PARAMETER num_ctx 8192
Monitor VRAM Usage
# Snapshot
nvidia-smi
# Live monitoring
nvidia-smi dmon -s u
# Full system view
btop
7. What is Quantization? {#quantization}
Quantization compresses model weights by representing each number with fewer bits:
float32 → 32 bits (full precision, huge size)
float16 → 16 bits
Q8_0 → 8 bits
Q4_K_M → 4 bits
Q2_K → 2 bits (noticeable quality loss)
Quality vs Size (9B model)
| Format | Size | Quality |
|---|---|---|
| float32 | 36GB | 100% |
| float16 | 18GB | ~99% |
| Q8_0 | 9.5GB | ~97% |
| Q5_K_M | 6.5GB | ~93% |
| Q4_K_M | 5.6GB | ~90% |
| Q2_K | 3GB | ~70% |
4B Q8 vs 9B Q4 — Which Wins?
4B Q8: 4 billion × high precision = fewer neurons, clean signal
9B Q4: 9 billion × lower precision = more neurons, slight noise
9B Q4 generally wins. The quality loss from Q4 compression doesn't outweigh the gain from having 2.25x more parameters. This holds especially true for reasoning and code tasks.
8. VS Code Integration {#vscode}
Ollama for VS Code
Install from the VS Code Marketplace — search "Ollama".
After installation:
Ctrl+Shift+P→ "Ollama: Select Model"- Choose your model
Ctrl+Shift+P→ "Ollama: Chat"
Tools Capability Not Showing?
Fix 1 — Clear the cache:
Ctrl+Shift+P → Developer: Reload Window
Fix 2 — Check the API directly:
curl -s http://localhost:11434/api/show \
-d '{"name":"your-model"}' | python3 -m json.tool | grep -A5 "capabilit"
If the API returns tools, the issue is just extension cache — Reload Window fixes it.
Fix 3 — Manifest issue:
Models imported from GGUF sometimes don't generate a manifest. Use a registry model as the base:
FROM qwen3.5:0.8b
# your parameters...
Continue.dev (Recommended)
For a more powerful VS Code integration, Continue.dev offers:
- Codebase indexing
- Automatic context awareness
- Tab autocomplete
- Native Ollama support
9. Cursor Integration {#cursor}
Cursor can't connect to localhost directly — it routes requests through its own cloud servers, which block private IPs (SSRF protection). The solution is exposing Ollama via a public URL.
Cloudflare Tunnel Setup
# Install cloudflared
curl -L https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64 \
-o /usr/local/bin/cloudflared
chmod +x /usr/local/bin/cloudflared
# Start tunnel (no account required)
cloudflared tunnel --url http://localhost:11434
Use the generated https://xxxx.trycloudflare.com URL in Cursor:
Cursor Settings → Models → Add Model
Base URL: https://xxxx.trycloudflare.com/v1
API Key: ollama
Model Name: your-model:v1
Point to Your Own Domain
If you have a Cloudflare account, you can route it through a permanent subdomain:
cloudflared tunnel create ollama-tunnel
cloudflared tunnel route dns ollama-tunnel api.yourdomain.com
Security note: Once you expose Ollama publicly, protect it. Use Cloudflare Access or add API key authentication to Ollama.
10. OpenWebUI Setup {#openwebui}
OpenWebUI gives you a ChatGPT-like interface that works seamlessly with Ollama.
Docker
docker run -d \
--network=host \
-v open-webui:/app/backend/data \
-e OLLAMA_BASE_URL=http://localhost:11434 \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main
Open http://localhost:3000 in your browser.
Docker Compose
version: '3'
services:
open-webui:
image: ghcr.io/open-webui/open-webui:main
network_mode: host
volumes:
- open-webui:/app/backend/data
environment:
- OLLAMA_BASE_URL=http://localhost:11434
restart: always
volumes:
open-webui:
docker compose up -d
11. Common Errors and Fixes {#troubleshooting}
❌ CAPABILITY tools → Parse Error
Error: command must be one of "from", "license", "template"...
Cause: CAPABILITY is not a valid Modelfile command.
Fix: Remove it. Capabilities are read automatically from GGUF metadata.
❌ Model Running on CPU
Check:
nvidia-smi
Fix: Add to Modelfile:
PARAMETER num_gpu 999
❌ 500: memory layout cannot be allocated
Cause: Not enough VRAM.
Fix: Reduce context:
PARAMETER num_ctx 8192 # or 4096
❌ CUDA error: out of memory
Cause: A previous model is still loaded in VRAM.
Fix:
pkill -f "ollama runner"
sleep 3
nvidia-smi
❌ Tools Not Showing in VS Code
Fix:
Ctrl+Shift+P → Developer: Reload Window
❌ Manifest File Not Found
GGUF-imported models may be stored under /usr/share/ollama/.ollama/ instead of /root/.ollama/:
find / -path "*/ollama/models/blobs*" -type f 2>/dev/null | head -5
❌ SSRF Error in Cursor
connection to private IP is blocked
Fix: Use Cloudflare Tunnel or ngrok to expose a public URL. See Cursor Integration.
Summary
Local LLM setup looks complex at first, but a few core principles make it manageable:
- Model selection: For 8GB VRAM, 9B Q4_K_M is the sweet spot
- GPU optimization:
num_gpu 999+ context balance is critical - Quantization: More parameters beats higher precision (usually)
- Integration issues: Usually a cache or manifest problem — Reload Window fixes most of it
- Cursor/remote access: Cloudflare Tunnel is the cleanest solution
Written by Batuhan Alkoç — learned by breaking things.